
Towards a superhuman driving agent
At comma research, our mission is to build a superhuman driving agent. A superhuman driving agent is one that can drive a car to your destination safer, more comfortably and more reliably than you can.
We believe a superhuman driving agent can be cleanly split into a planner and controller. The openpilot team maintains a classical controls stack that should be sufficient for superhuman driving. So comma research just needs to build a planner that takes in video and tells the controller where and how fast to drive. Ideally, this planner should be written completely in software 2.0. The three major parts of building this planner are collecting data, annotating data and finally training a planner.
While we work towards superhuman driving capabilities, openpilot is an always improving level 2 self-driving system. This means the driver needs to pay attention at all times, which is encouraged by a driver monitoring system.
Collecting dataPermalink
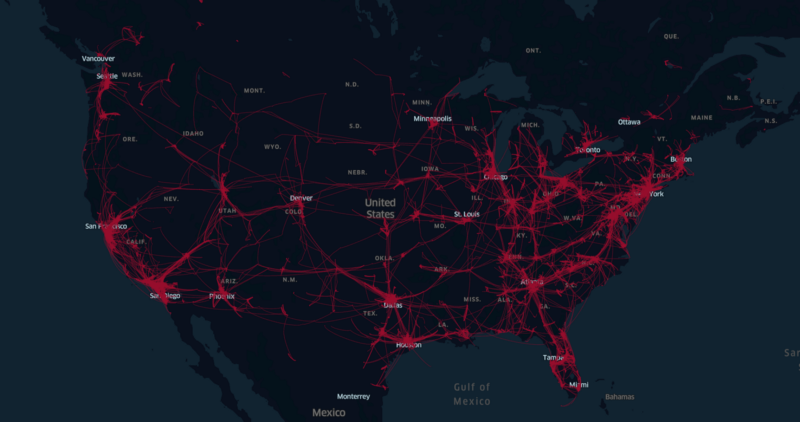
Making a superhuman planner requires data. To satisfy these data requirements openpilot constantly logs camera footage of the road and readings from a variety of sensors, these logs are then uploaded to our servers. Currently, tens of thousands of kilometers are driven with openpilot across the globe every day, contributing to a dataset of already over 20 years of continuous driving experience. We believe this dataset to be a fairly complete representation of the driving problem.
Annotating dataPermalink
The raw data is not immediately useful. It needs to be processed and annotated to be used for training, testing and general data analysis. This annotation includes 3D localization of every video frame, semantic segmentation, detecting of lane changes and much more. All this data annotation is done automatically, human labeling does not scale.

It is solving this part of the problem that has lead to the open-sourcing of a dataset, a GNSS processing library and a kalman filter library for high-performance visual odometry.
Training a plannerPermalink
Most attempts at making a superhuman planner involve making a perception stack to detect certain human understandable aspects of the environment, such as cars, pedestrians and lanes. A planning stack then makes plans based on these perception outputs. The problem with this approach is that the planner is limited to only make plans based on what is described in the hand-coded perception layer, which is doomed to be never good enough.
We believe the most promising way to make a superhuman planner is to make a planner that mimics human policy. The underlying assumption is that human mistakes are generally deviations from the mean. So a planner that learns to predict the the most probable human policy for every scenario will make less mistakes than a human.
When building an end-to-end planner, it is a good idea to have a compressed representation of a driving scene. As long as it is a learned set of features, not a hand-coded set of features. To achieve this we train **vision models **that compress all information relevant to planning from an image into a feature vector.

Finally we can train Recurrent Neural Networks that generate driving policy from a sequence of these feature vectors. There is a lot of nuance in this step that is quite important. The planning models are trained in a noisy simulator to ensure they are trained on-policy and are resilient to noise. Finding loss functions that can accurately reflect whether machine policy mimics human policy is also a continual challenge, currently openpilot models use variations of Mixture Density Networks.
Driver MonitoringPermalink
Lastly, as long as openpilot is not superhuman all the time, it is important for openpilot to confirm the driver is always ready to take over control of the car when needed. It is the research division’s responsibility to build and maintain a system that can monitor the driver’s attention level and alert an inattentive driver accordingly.
Like the planning model, the driver monitoring neural network is vision-based and trained on video footage from openpilot users that decide to upload it. This video is also annotated with automatically generated ground truth using a combination of open-source and custom neural networks.
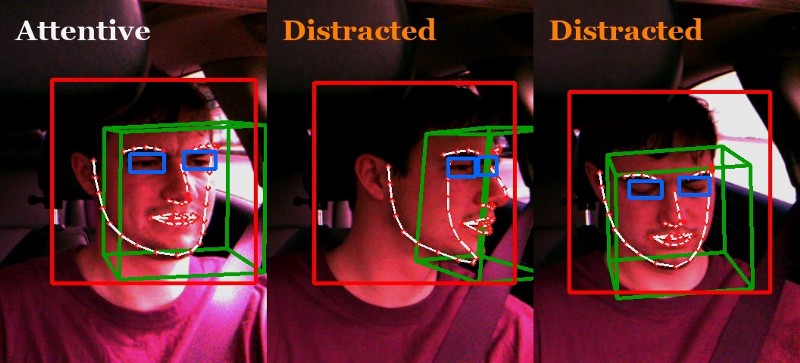
openpilot’s abilities will become superhuman gradually. It will first become superhuman in some parts of some drives (level 3 self-driving), then all parts of some drives (level 4) and finally all parts of all drives (level 5). Driver monitoring will play a crucial role during this transition, by clearly communicating with the driver when it is safe to relax and when more attention is necessary. Already, the strictness of openpilot’s driver monitoring policy depends on road conditions.
Join the teamPermalink
If you are excited by the things described here and have relevant experience, apply for a job in the research division!
Harald Schäfer,
Head of Research @ comma.ai
Leave a comment