
Development speed over everything
Any software project that lets development become slower and harder as the quality of the product increases will eventually stagnate. It is critical that improving our code without introducing regressions is and remains easy forever. If we can improve openpilot today at the cost of future progress, it’s not worth it. In practice this means that the majority software development time at comma is spent on tests, tools, infrastructure, and deleting code.
In the blog post I will outline some of the things we’ve focused on to ensure a good and fast development environment, as well as a concrete example of what it takes to make and deploy a small change to our neural network architecture.
Simple codePermalink
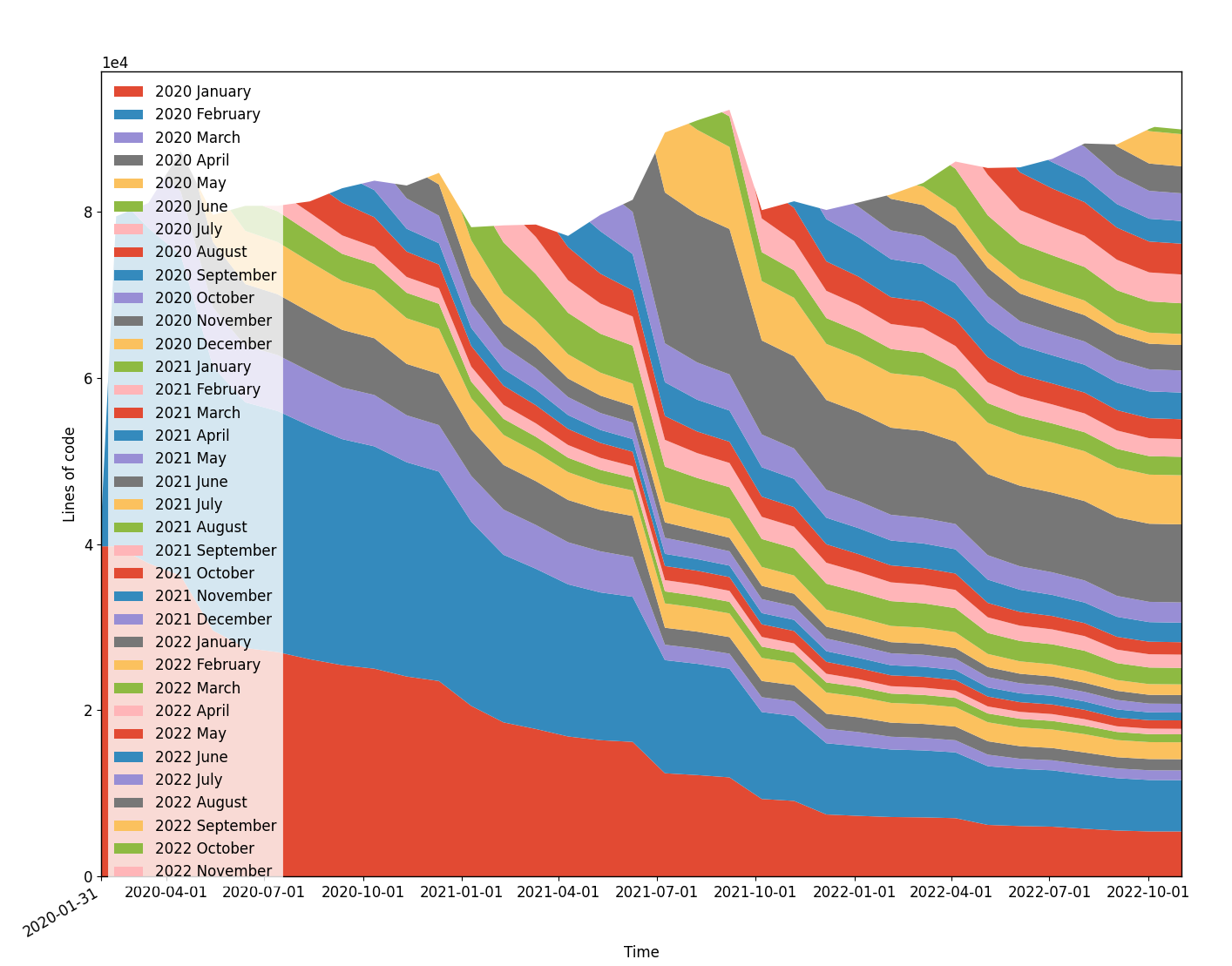
For code to be easy to work on it needs to be simple, readable, and use good abstractions. We’ve spent a tremendous amount of effort to manage the complexity of our codebase. One way to look at the complexity of a codebase is to look at the total of lines of code. Line count isn’t a perfect metric, but paired with good programming practices it serves as a decent proxy for complexity. Below you can see the churn graph of all of the C, C++, and python code in the openpilot repository. You can see the total line count barely increased over 30 months, while openpilot went from supporting ~50 car models to 200+, and improved in countless other ways.
Outside of openpilot, we’ve developed several other projects that all have a strong focus on achieving the task while keeping code complexity to an absolute minimum. Laika for GNSS processing, rednose for kalman filtering, minikeyvalue value for distributed data storage, and most recently tinygrad for deep learning.
Continuous integration testingPermalink
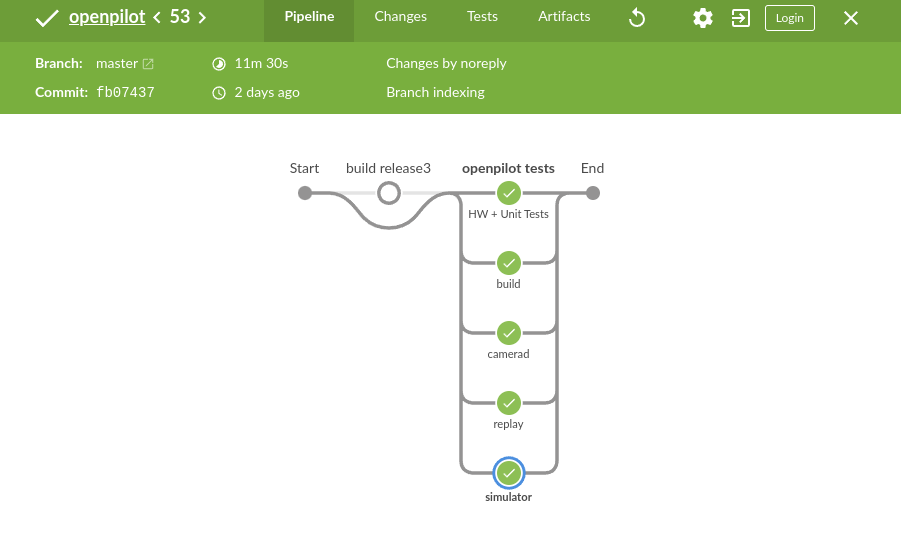
Simple code isn’t everything. Even the best engineers working on the simplest code, make mistakes. Having complete, fast, and reliable CI testing can point out bugs quickly without having to waste time debugging. CI in openpilot runs tests across the entire stack, including tests that run on dedicated comma threes running simulations while tracking all sorts of performance including CPU usage, thermals, etc…
Software 2.0Permalink
End-to-end machine learning is at the core of comma’s approach to self-driving. Machine learning allows us to avoid writing a lot of complex logic, and instead just work neural network training code with goal functions and letting the neural networks figure out the rest.
24hr modelsPermalink
A lot of openpilot’s behavior is determined by the neural network models we train. To make sure we can iterate quickly when making changes to the models, it’s critical that the models train quickly. Generally speaking models are better when they train longer, but once you’ve shipped a model that took a week to train it can be very hard to make a model that’s better without also letting it train for a week. If model iterations would take a week, that would be a bottleneck in the development speed of improving models.
To ensure we only ship models that train fast, we introduced the following piece of code in our universal pytorch training script, which kills your training task if it takes too long. It’s easy to circumvent, but it encourages good practice.
# 24HR AUTOKILL
total_time = time.monotonic() - start_time
if total_time > 60*60*24:
print('Your training run took over 24hrs and was killed')
break
Training testsPermalink
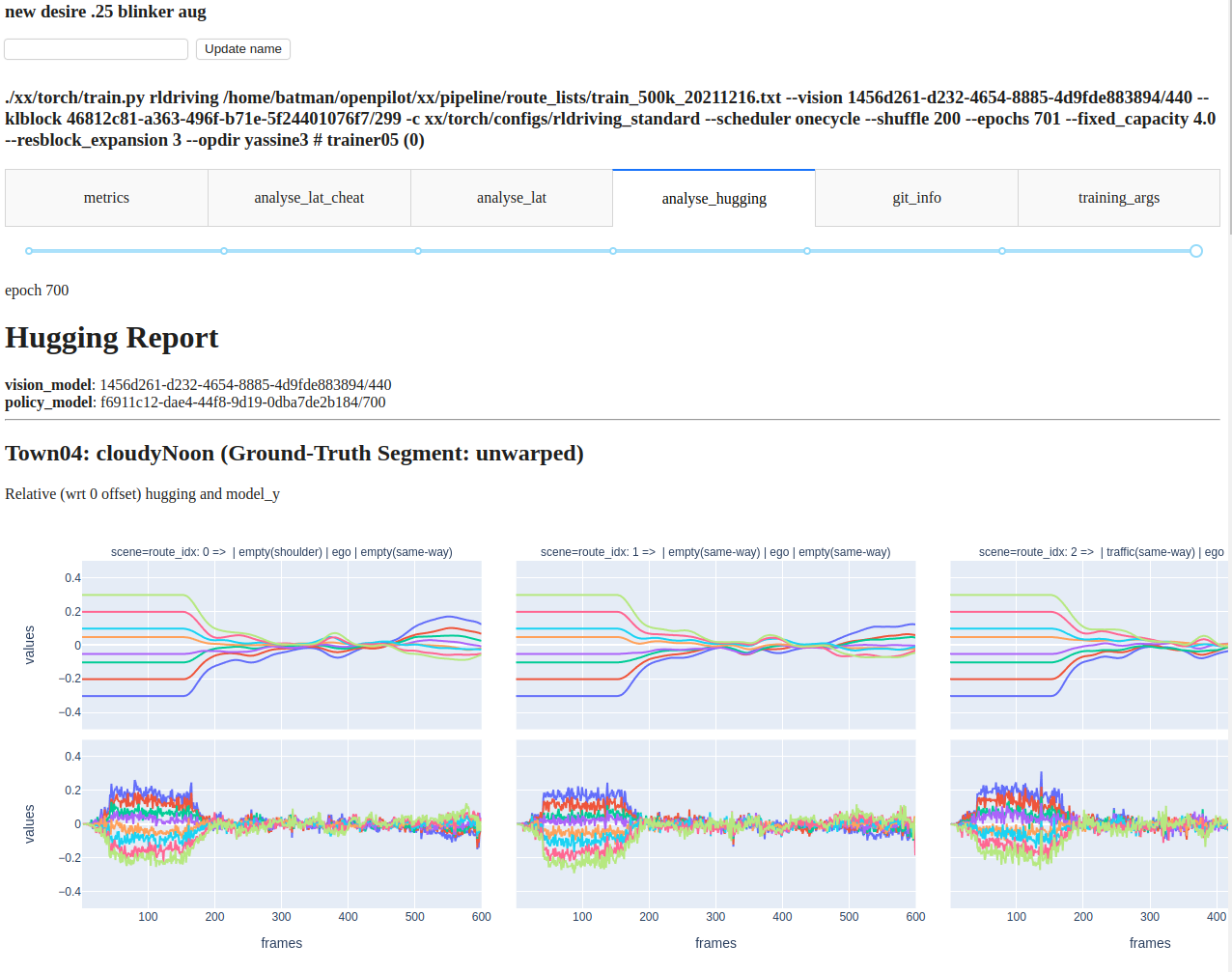
The 24hr training limit helps keep model iterations relatively fast, but it’s important to understand how well a model will perform in the real world without needing to test in a car, or even waiting for the training run to finish. Our model trainers run test suites that capture the full range of openpilot’s behavior at various intervals during training automatically. This way we can generally know how the model will perform in the real world without manually needing to run any tests.
Local compute clusterPermalink
At our new office we have a beautiful new compute cluster. This compute cluster has ~3 petabytes of SSD storage, ~450 GPUs, ~5000 CPUs, and a 10Gbit connection to our workstations. Using local compute is cheaper than running a similar amount of compute in the cloud. Owning the compute cluster also means we can customize it to be optimal for our purposes. And lastly, because we buy compute rather than renting it in the cloud, most of the cost is upfront and not variable. This low cost to using the servers encourages experiments and development.

Example: Keyboard to car in a few commandsPermalink
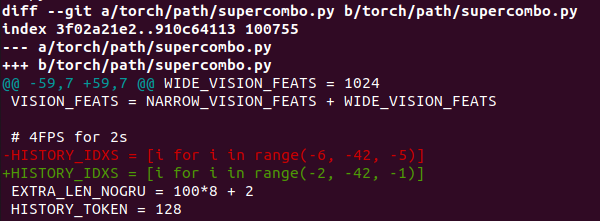
Recently I made an experimental change to our driving model, which changed the amount of historical context (information from previous images) the driving model takes in to determine where to drive. It changes the input context from 8 image pairs (2s at 4FPS) to 40 image pairs (2s at 20FPS).
This required the following git diff in our model architecture:
With this change we can run a command to dispatch a model training job on a training machine.
./xx/torch/train.py rldriving /home/batman/openpilot/xx/pipeline/route_lists/train_500k_20211216.txt --vision 1456d261-d232-4654-8885-4d9fde883894/440 --klblock 46812c81-a363-496f-b71e-5f24401076f7/299 -c xx/torch/configs/rldriving_standard --scheduler onecycle --shuffle 200 --epochs 701 --fixed_capacity 4.0 --resblock_expansion 3 --opdir harald
This trainer requires driving to be simulated in the training loop, to be sure the model can be robust to its own mistakes. The trainer automatically starts rollout workers on the entire compute cluster to start producing training data. With all the training tests and metrics we can evaluate the model during training and confirm that everything appears to be going well. With the recent compute cluster improvements the job is done in less than 10 hours!
Now the model is ready to compile, which we do with the following command, and then some git commands to commit the changes to an openpilot branch.
./xx/ml_tools/snpe/compile_torch_nogru.py 1456d261-d232-4654-8885-4d9fde883894/440 3f048943-28b5-4471-8ac5-d3a4fe9e4773/700
git branch full_hist
git checkout full_hist
git add selfdrive/modeld/models/supercombo.onnx
git commit -m "1456d261-d232-4654-8885-4d9fde883894/440 3f048943-28b5-4471-8ac5-d3a4fe9e4773/700"
git push
Now in theory the openpilot branch should be ready to drive on in a car, but unfortunately it fails compilation on the device which we can see in the openpilot CI test, which fails with the following error.
File "/usr/local/pyenv/versions/3.8.10/lib/python3.8/site-packages/pyopencl/__init__.py", line 583, in _build_and_catch_errors
raise err
pyopencl._cl.RuntimeError: clBuildProgram failed: OUT_OF_HOST_MEMORY - clBuildProgram failed: OUT_OF_HOST_MEMORY - clBuildProgram failed: OUT_OF_HOST_MEMORY
Build on <pyopencl.Device 'QUALCOMM Adreno(TM)' on 'QUALCOMM Snapdragon(TM)' at 0x7f5b524508>:
This due to an inefficient architecture choice during compilation. This could have been anticipated if on-device compilation was tested during training, or during CI of the commit that changes the training behavior. Something we will work to improve in the future. Either way, the following git diff fixes compilation.
We now repeat the compilation and git commands. And all we have to do to run it on a test car, like our rav4, is:
./xx/chffr/ssh/connect.py rav4
git checkout full_hist
sudo reboot
And now it is ready to drive on in a car. All this change took was a handful of commands, with tons of automatic checks running along the way. This was an easy change, but hopefully it gives you an idea of what it’s like to make changes in our development environment, that we’ve been working so hard to improve.
Written by: Harald Schäfer
Leave a comment