
End-to-end lateral planning
The goal of the research team at comma is to build a superhuman driving agent. We’ve discussed before how we believe the most effective way to build a superhuman system is to build an end-to-end planner that mimics human driving. So far openpilot has relied heavily on classical perception to detect lanelines and lead cars to make driving decisions. Eventually we want lateral and longitudinal planning to be done fully end-to-end, but our recent focus has been on lateral planning.
The latest release of openpilot, 0.8.3, includes a new model that can do high quality lateral planning and was trained fully end-to-end. This post will give an overview of how these models work and the challenges involved with getting to this point.
What is e2e and why is it hard?Permalink
A simple approachPermalink
We call a model e2e (end-to-end), when it takes in images/video and outputs how you should drive, in our case the model outputs a trajectory of where to drive in 3D space. This trajectory is represented by x, y and z coordinates in meters, and we leave it to a controller to execute this trajectory.
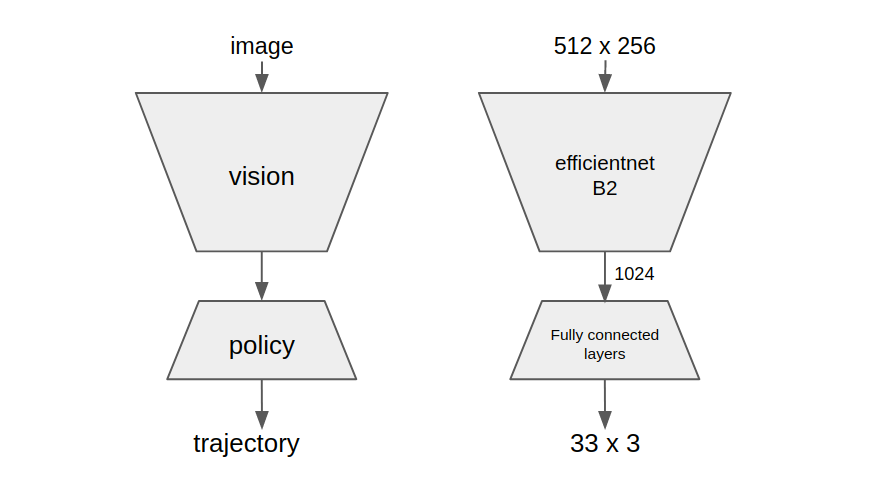
The simplest approach one can imagine, is to collect a lot of data of humans driving, and then train a model that takes in video and predicts the trajectory the human drove for every situation. We use a type of MHP loss, to make sure the model can predict multiple possible trajectories. We start with a fully-conv efficientnet B2 block that reduces down to a 1024-dimensional vector, we call this block a vision model. This feature vector then goes into a block containing a few fully connected layers that we call a policy model.

A simulatorPermalink
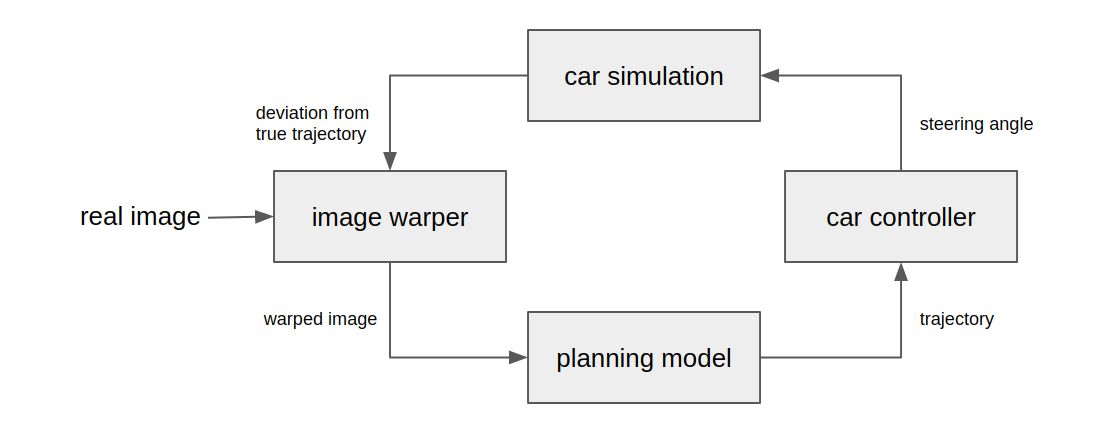
Testing whether things work in the real world is rather inefficient, so we use a simulator. We use a simulator that takes in real-world video and computes how openpilot would behave with a certain model. The model predicts where you should drive, the controls stack computes the ideal steering angle to achieve that trajectory and a simple physics model then calculates how the car would move with that steering angle.
Moving around in the simulator
After one iteration of this loop, the input video now needs to be modified to reflect the movement of the car. This is the difficult part. One could run this in a simulation environment like CARLA, where the engine allows you to move the vehicle as you please and give you new camera perspectives. However, this would restrict the diversity of testing to what CARLA can simulate, we would be blind to a lot of potential real-world failures. Instead we opted to use real-world video and augment it to make it look as if the car is moving in the way we want it to. There are many ways to do this, but we just apply a simple warp to the image, assuming the whole scene is in the road plane. For any large movements this seriously distorts the images, but for small deviations this works well.
The problemPermalink
Now we have a simulator, we can test how the simple approach would perform. As you can see in the video below, it mostly correctly predicts where the human drove, however it still doesn’t stay on track well. And when we introduce some slight real-world noise (steering lag, wind, etc…) things get dramatically worse.
Driving with the simple model and no added noise (left) and realistic noise injected (right)
What exactly is going here is worth a whole discussion in itself, but we’ll try to shed some light on it with a simple thought experiment. The simple models described above predict where a human is most likely to drive given some driving video. Imagine a long straight highway lane, where a human is perfectly centered in the lane. The human is most likely to keep driving completely straight, so that is what our model will predict. However, imagine the human was for any reason 10 cm away from the center, what is the human’s most likely trajectory now? It is still completely straight.
If you accept that claim, you can quickly see how a model that just predicts a human’s most likely trajectory does not predict how to recover from mistakes. If the car deviates from the ideal trajectory for any reason, the model does not predict a trajectory that recovers back to the human trajectory. And so, when there is any noise that causes the car to deviate from the planned trajectory, there is no pressure to recover and the car keeps drifting away from the ideal trajectory. In practice there is always noise, even in a simulation where we don’t introduce noise, there are linearization errors, model prediction errors, rounding errors, etc…
Our approachPermalink
Learning in a simulatorPermalink
To solve the problem, we need to find a way to train a model such that it can predict how to recover from any deviations from a good trajectory. One way to do this is to use the simulator described earlier. We can introduce noise, so the car moves away from the ideal trajectory, and we can then train a model to predict where the human trajectory is from this new perspective. For our purposes we always consider the human trajectory to be ideal.
Drifting around in a noisy sim with the simple model’s predicted trajectory (white) and human trajectory (black)
You can see this in action in the video, we make the car drift around, but show the model where the ideal trajectory is regardless of its own position. Let’s apply the earlier thought experiment to this model. If the car is 10 cm away from the center of the lane the model will now predict a trajectory closer to the center of the lane. If we let a controller execute on that trajectory, it will recover.
Driving in a noisy simulation with a model trained in noisy simulator, it drives well
Cheaters, a new problemPermalink
The solution above seems like it works, but it has a new hidden problem. It works in simulation, but only in simulation. Our simulation method just warps the image to make it seem as though the car is moving sideways. This method introduces a lot of artifacts.
Obvious simulator artifacts
We consider the ideal trajectory to be the one the human actually drove. This means that during simulation, when you are on the ideal path the image is unwarped. So to figure out where the ideal trajectory is, all the model has to learn is how much and in which direction the image is warped. It is much easier for the model to learn the warping artifacts and see how the image is warped than to learn where humans would drive for a given scene. So the end result is a model that just predicts you are on the ideal trajectory if the video doesn’t look warped. When you actually use this model in real life, it ends up always predicting you are on the ideal trajectory and never recovering from any mistakes. These models just learned to do well in the tests, but never learned the real task we wanted them to, so we call them cheaters.
The KL SolutionPermalink
We need to make sure our models learn where to drive and not just how to exploit simulator artifacts. To solve this, we could try to make a better simulator that doesn’t have obvious artifacts, but this is incredibly hard. Instead, we try to make the model blind to the artifacts of the simulator.
Pull the kale over the model’s eyesPermalink
Imagine a feature vector that contains all the information of a certain road scene that is relevant to trajectory-planning, but no information about anything else, such as any potential simulator artifacts. If we just train the vision model with the simple approach described above and take the feature vector it outputs, that vector should contain most of the information relevant for trajectory-planning. This feature vector is uninterpretable to us, but we know it must contain that information because the policy models can generate good trajectories from it.

Unfortunately, our tests indicate this vector does still contain information about how the image is warped. To remove that information we apply a KL-divergence loss to this feature vector at train-time. This loss makes the vision model minimize the information content in the feature vector. When this loss is weighted appropriately, the vision model will preserve information that is relevant for trajectory-planning since that is needed to do well on the trajectory-prediction loss function and reject everything else. The resulting feature vector only contains information relevant to the problem it is trained on, which is trajectory-planning on unwarped images.
We can now train a new model in the simulator, we reuse the part from the vision model that compresses it to a minimal vector and keep that part frozen. We just train a new policy model. We want the model to have some temporal context, so we add a GRU block in the policy model as well. Now it will learn where it should drive without exploiting the warp. This model now works in simulation and real life.
Try it!Permalink
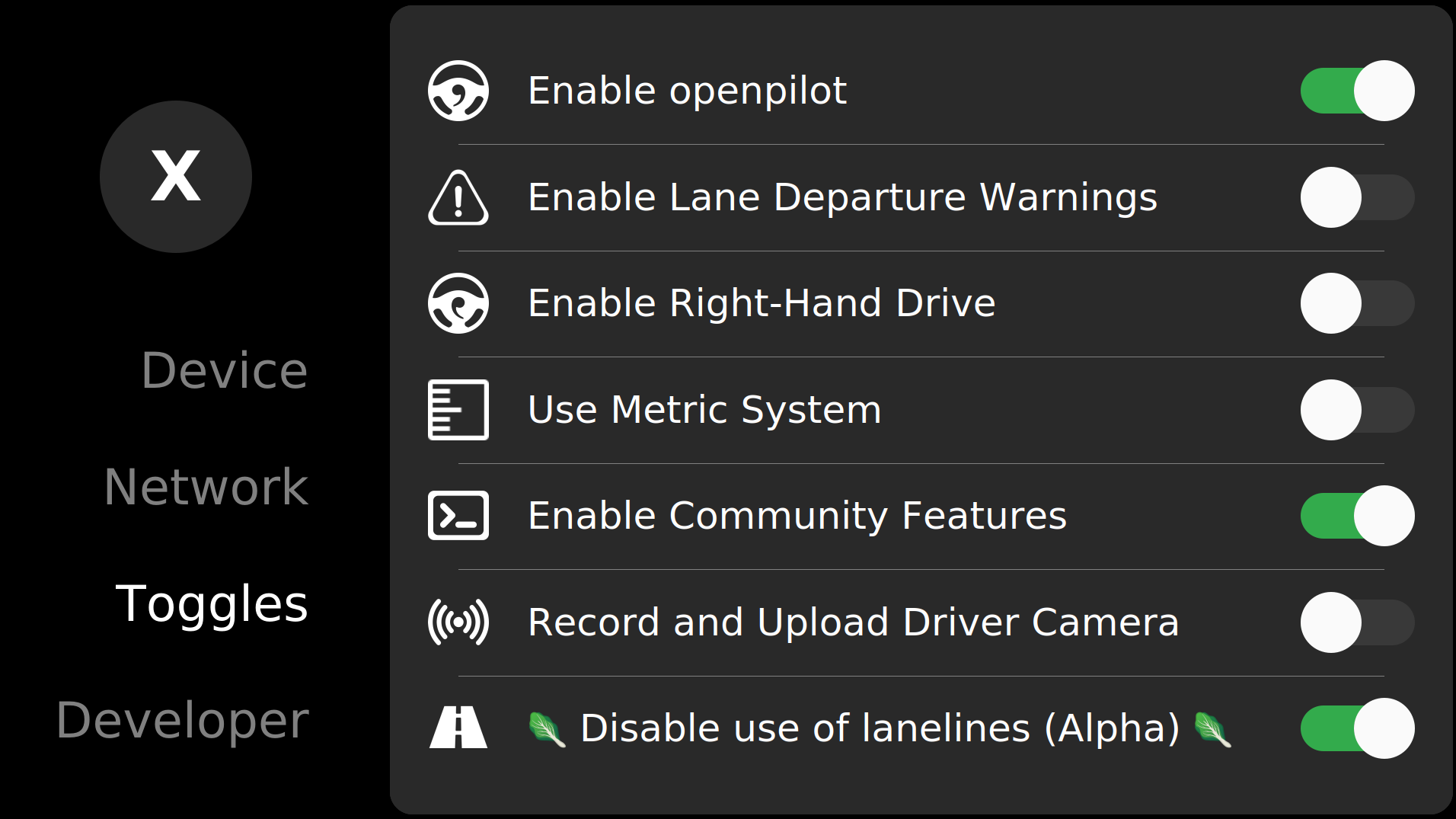
The 0.8.3 release of openpilot includes a toggle that disables the use of lanelines. In this mode openpilot will only use this e2e-learned trajectory for lateral control. Experience the magic yourself!
Join usPermalink
Are you interested in joining the comma research team? Try the hiring challenge!
Harald Schäfer,
CTO @ comma.ai
Leave a comment